
Large Language Models (LLMs) have achieved remarkable performance in most natural language processing downstream tasks, such as text understanding, text generation, machine translation, and interactive Q&A. However, the billions or even trillions of model parameters pose significant challenges for efficient deployment of LLMs at the edge. With the growth rate of model parameters far outpacing the improvement in hardware performance, the academic and industrial communities are exploring software and hardware collaborative methods like model compression, dataflow optimization and operator invocation to deploy and run large models under the limited hardware conditions.
Given the rapidly increasing demand for deploying large models at the edge and the generality of computing resources, deploying large models on CPU architecture processors has become one of the important development directions. The industry has recently been releasing large models that can be deployed on edge devices, further promoting this technological trend and attracting more developers from academia and industry. How to systematically optimize large models to cope with insufficient hardware performance has become a key issue for efficient inference of large models at the edge. Due to the fact that most of the edge devices run on Arm-based CPUs, 2024 AICAS conference organizes this grand challenge on software and hardware co-optimization for general LLM Inference on the YiTian 710 CPU of the Arm V9 architecture as the computing power platform, aiming to promote and drive the related technologies.
A. Grand Challenge Scheme:
B. Important Dates:
C. Registration for the AICAS Grand Challenge 2024:
D. Awards:
E. Workshop for Finalist Teams:Participants will work on the Qwen-7B large language model and propose methods from various aspects, such as model compression, parameter sparsity, model quantization and structural pruning. In addition, combining the hardware features of the Arm architecture and the open-source software resources (such as hardware BF16, vector matrix multiplication and Arm Compute Library) to systematically optimize and enhance the model's inference performance on hardware. The participants' optimization methods will be scored based on a testing scheme designated by the competition's organizing committee.
Qwen is a LLM officially released by Alibaba Cloud Computing Co. Ltd., with parameter scales ranging from billions to trillions. The comprehensive performance of this model is well-rounded in mainstream benchmark evaluations. Among them, the 7-billion-parameter general-purpose model Qwen-7B and the dialogue model Qwen-7B-Chat are open-source and free versions. Alibaba Cloud provides multiple global channels for accessing the models. Besides, Alibaba Cloud also provides related procedures for Qwen LLM training, deployment, and inference.
For the preliminary stage of the competition, the organizing committee will not provide any specific datasets. Participant teams are free to choose open-source datasets for training and fine-tuning. Additionally, no particular hardware platform is specified for this stage. Teams have the autonomy to select their hardware platforms for validating their large model optimization methods. They will conduct a comprehensive performance evaluation, comparing the Abilities and Efficiencies of the deployed LMM performance before and after optimization. 32 teams will be shortlisted to the next round based on the preliminary score ranking of the participating teams and the results of code reviews.
During the final stage, the organizing committee will provide a specified dataset, which is yet to be confirmed. The participating teams will carry out software and hardware collaborative optimization for large models based on the unified YiTian 710 CPU provided by the organizing committee. Teams will propose targeted algorithm inference and deployment strategy optimizations, followed by a comprehensive performance evaluation and a before-and-after comparison of the deployment.
Competition Workshop*: After the preliminary round, the organizing committee will hold a competition workshop in China, inviting the finalist teams to participate. The conference will invite experts from the organizers to give a keynote speech and arrange networking activities. The organizing committee will reimburse the travel and accommodation expenses incurred by the participating teams for attending the workshop (subject to meeting the cost standard requirements).
AICAS Conference & Ceremony**: After the semi-final round, the organizing committee will invite the winning teams to the main venue of the 2024 AICAS in the United Arab Emirates for a defense and to participate in conference activities. The organizing committee will reimburse the travel and accommodation expenses incurred by participating teams for attending the symposium (subject to meeting the cost standard requirements).

| Evaluation aspect | Contents | Evaluation approach |
|---|---|---|
| Model Ability |
|
Participants are required to run the analysis tool lm-evaluation-harness locally to evaluate their model's performance. This tool will generate a json file containing the performance data, which will be used for further evaluation in the competition |
| Model Efficiency |
|
Participants are required to run the analysis tool optimum-benchmark locally to evaluate their model's performance. This tool will generate a CSV file containing the performance data, which will be used for further evaluation in the competition. |
Accuracy: The models' performance will be evaluated using open source testing tool lm-evaluation-harness to run the following test datasets locally: ARC_challenge\HellaSwag\Piqa. For the scoring criteria, the average score of QWEN-72B on chosen test datasets will be used as PMax, and the average score of QWEN-7B-INT4 on the same test datasets will serve as PMin. If a participant's model score is lower than PMin, it will be considered as not scoring in the model accuracy optimization aspect. The specific calculation formula is as follows:
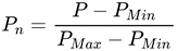
This metric is the percentage of the number of parameters before and after model compression. The original size of the QWEN-7B model is taken as Mori, and the size of the optimized QWEN-7B model as Mopt. The highest compression rate, CR, among all competing teams, will be used as the normalization parameter. The specific calculation formula is as follows:
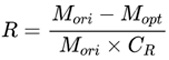
This encourages participants to propose new methods for inference optimization. The organizing committee will compare the improvement ratio of inference time before and after optimization. The initial latency acceleration rate is denoted as Lori, and the post-optimization latency acceleration rate as Lopt. The highest value of latency acceleration rate, CS, among all teams will be used as a normalization parameter. The specific calculation formula is as follows:
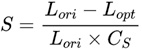
The change in the model's throughput before and after optimization is analyzed using the open-source tool Optimum-benchmark. The original throughput of QWEN-7B is represented as Tori, and the throughput after optimization as Topt. The highest throughput value among all teams, denoted as CY, will be used as the normalization parameter. The specific calculation formula is as follows:
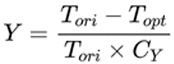
The scores in the competition will be weighted summed. The specific formula for this calculation is provided in the document, detailing how different aspects of the participants' model performance will be combined to derive their summed score:
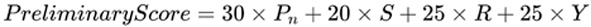
The submission requirements at this stage for the competition include:
In the final stage, teams are required to deploy and optimize the LLMs on the unitive Arm architecture hardware platform. (The specific platform information will be announced by the organizing committee) They must use the dataset provided by the organizing committee to evaluate model inference accuracy, performance, and hardware resource utilization. The hardware resource utilization evaluation involves normalizing the CPU computing resources (core numbers, thread counts, etc.) and storage resources (memory usage, disk space, etc.) occupied by each team's optimized model on the unitive platform. The maximum and minimum resource usages from all submitted final results are denoted as HRMax and HRMin, respectively. The specific calculation formula for this evaluation is as follows:
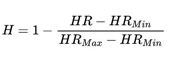
During the final stage, teams will use the dataset provided by the organizing committee to evaluate their model's inference accuracy, inference performance, and hardware resource utilization. The specific formulas for calculating these metrics are detailed in the document. These formulas will guide the evaluation of each team's optimization efforts in terms of model accuracy, performance efficiency, and the extent of hardware resources used:
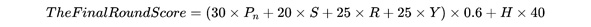
The final rankings and prize distribution of the competition will be based on the scores obtained in both the preliminary and final rounds. The final scoring formula, as shown in the document, combines these scores to determine the overall ranking of the teams. This formula encapsulates various factors evaluated during the competition stages:
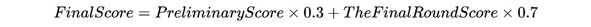
After the final round of the competition, teams need to submit:
Note: The submission limit for the preliminary round and the final round is 5 times per day.
To foster open science and the sharing of resources within the IEEE community, IEEE launched IEEE DataPort, a platform for exchanging data globally. Through this initiative, researchers will be able to store, share, and access datasets across various disciplines, thereby enhancing collaboration and accelerating scientific discovery.
For this year's grand challenge, we are introducing a new Bonus Award to encourage the use of open-source data and IEEE DataPort. Participants are highly encouraged to open-source their proprietary datasets in the LLM tuning. Teams need to create and submit a new dataset (including data files, background information, and usage instructions) to the IEEE DataPort platform (https://ieee-dataport.org/). Upon successful upload, participants are required to forward their dataset's web link to the organizing committee (contact: Yuhang Zhang, yhzhang0916@sjtu.edu.cn and Zhezhi (Elliot) He, zhezhi.he@sjtu.edu.cn).
Bonus Award will be evaluated based on the Dataset Quality and Viewership:
| Items | Dataset Quality | Viewership | ||
|---|---|---|---|---|
| Richness&Timeliness | Accuracy | Understandability | ||
| Score | 0-30 | 0-30 | 0-30 | 0-10 |
The total score is the sum of Dataset Quality Score and Viewership Score. The highest-scoring team will be deemed the winner.
The winner of the Bonus Award will receive a prize of 500 USD and the opportunity to be invited to IEEE Data Descriptions, IEEE’s pioneering data descriptor periodical.

Nanjing University, China

Nanjing University, China

Xidian University, China

Xidian University, China

Shanghai Jiaotong University, China

Alibaba Group
Alibaba Group
Arm China
Arm China
Abu Dhabi, UAE
aicas2024@ku.ac.ae
xx xxx xxx xxx
©2024 Khalifa University. All Rights Reserved